In recent years, medium to large size organizations are facing the same problems with data silos available across different departments. Even some of them are having the Enterprise data warehouse, but there are missing pieces outside the data warehouse like social media information, weblog, etc.
Figure 1: Typical Example of Data Silos by Department
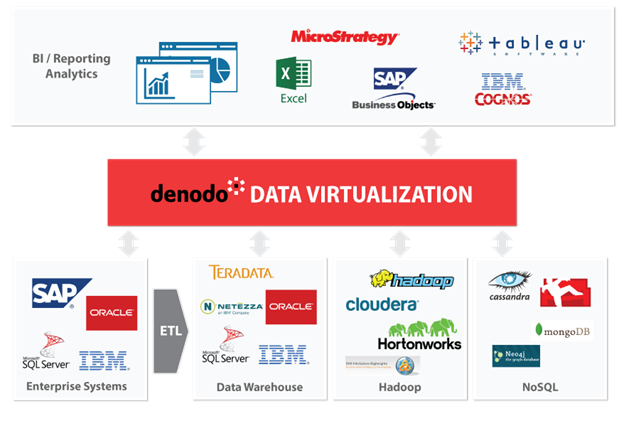
Thus, there is a need to build a data lake for hosting all available data. Unfortunately, there is no golden standard for data lake up to this moment. However, I think the Data Virtualization may take a vital role for the data lake due to lots of different types of data. Data virtualization tool could link up the relationships between NoSQL database, data warehouse and other database sources with a logical view. This logical view is able to be connected as a normal data source for easy exploration for data scientists. Once there is any important finding, it is possible to expand the data warehouse to feed the valuable data for regular and further analytics.
However, it is important to highlight the DENODO Data Virtualization as one of the leaders in the industry. It is still a good idea to use DENODO Virtualization with other ETL tools like IBM DataStage, Talend, etc. for building your own complete solution.
Figure 2: DENODO – Logical Data Lake
At this point, you may ask which is the best solutions. There are several key considerations to be accounted:
1. Data Governance & Metadata – core value for the single view of truth
2. Security – row / column level and role / group level
3. Performance – mainly related to the caching ability
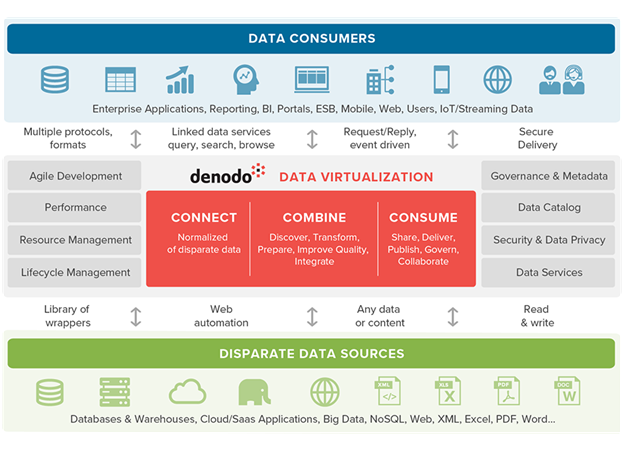
Additionally, it is better to pick up tools with higher flexibility and avoid single vendor to dominate the whole corporate environment to prevent future robbery by a single vendor. As a team of data science professional, Denodo is being selected as our recommended solution. Please check with the architecture diagram as the answer of the pain-points of data silos by Denodo.
Figure 3 DENODO – Architecture
Nevertheless, Enterprise data virtualization tools are not cheaply available. At this moment, there is only 1 free-of-charge choice by Apache Foundation called Apache Drill for Hadoop & NoSQL only (no relational database). It is still worth to try. For paid data virtualization, you should check with the performance, number of data connectors, technical support service quality, pricing and local partner / vendor implementation ability – better to have extensive architecture experiences on database, data warehouse and hadoop.
Conclusion
In a nutshell, it is important to understand data lake before making any further investments. Data lake maintenance is very costly by replication more & more data overtime.
If you have the needs with a data lake with all available data, you should go ahead by implementation in phases. Moreover, Data Virtualization tool could be valuable for connecting the data relationship across different areas of the data lake for fast data access. In the long-run, you may consider additional data integration jobs for such situation – by enriching the data warehouse (feeding with unstructured data or other sources).