Unraveling Data Lake and Data Virtualization: A Comparative Analysis for Solving Data Silos
Introduction:
In the age of big data, organizations face the challenge of managing vast amounts of diverse data sources stored in disparate systems, leading to data silos that hinder data integration and analysis. Data lake and data virtualization are two distinct approaches employed to address this issue and unlock the full potential of enterprise data. In this comprehensive guide, we’ll delve into the concepts of data lake and data virtualization, compare and contrast their features, benefits, and use cases, and provide insights on when to use each approach based on specific business requirements.
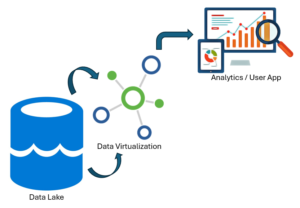
1.Understanding Data Lake:
1.1 Definition:
– A data lake is a centralized repository that stores large volumes of structured, semi-structured, and unstructured data in its native format, without the need for pre-defined schemas or data models.
– Data lakes are designed to accommodate diverse data sources, including logs, sensor data, social media feeds, and transactional databases, enabling organizations to ingest and store data at scale for downstream analytics and data exploration.
1.2 Key Characteristics:
– Schema-on-read: Data lakes support schema-on-read architecture, allowing data to be stored in its raw form and structured upon retrieval to meet specific analysis requirements.
– Scalability: Data lakes are highly scalable and can accommodate petabytes of data, making them suitable for storing and analyzing large volumes of diverse data types.
– Flexibility: Data lakes offer flexibility in data ingestion and storage, allowing organizations to capture and store data from various sources without upfront data transformation or normalization.
1.3 Use Cases for Data Lake:
– Clickstream Analysis: E-commerce companies use data lakes to store web server logs and user interaction data, enabling analysis of customer behavior and preferences for targeted marketing and personalized recommendations.
– IoT Data Management: Manufacturing companies leverage data lakes to ingest and analyze sensor data from connected devices and machinery, enabling predictive maintenance and process optimization.
– Data Science and Machine Learning: Data scientists use data lakes as a centralized repository for storing raw data and training datasets, facilitating exploratory analysis, feature engineering, and model development.
2. Exploring Data Virtualization:
2.1 Definition:
– Data virtualization is an approach to data integration that enables unified access to distributed data sources without physically moving or replicating the data.
– Data virtualization platforms create a virtual layer that abstracts and integrates data from disparate sources in real-time, providing users with a unified view of data across the organization.
2.2 Key Characteristics:
– Real-time Data Access: Data virtualization platforms provide real-time access to data from diverse sources, including databases, cloud applications, and APIs, without the need for data replication or movement.
– Data Federation: Data virtualization enables data federation by integrating and combining data from multiple sources on-the-fly, allowing users to query and analyze data seamlessly.
– Agile Data Delivery: Data virtualization supports agile data delivery by providing self-service access to integrated data assets, empowering users to query and analyze data in a flexible and efficient manner.
2.3 Use Cases for Data Virtualization:
– Customer 360 View: Enterprises use data virtualization to create a unified view of customer data by integrating information from CRM systems, marketing databases, and customer support platforms, enabling personalized customer experiences and targeted marketing campaigns.
– Regulatory Compliance: Financial institutions leverage data virtualization to achieve regulatory compliance by integrating and federating data from disparate systems to generate consolidated reports and audits in real-time.
– Operational Analytics: Retailers use data virtualization to integrate data from point-of-sale systems, inventory databases, and supply chain management systems, enabling real-time analytics and decision-making to optimize inventory levels and product offerings.
3. Comparing Data Lake and Data Virtualization:
3.1 Architecture:
– Data Lake: Data lakes follow a centralized repository architecture, where data is stored in its raw form and structured upon retrieval based on analysis requirements.
– Data Virtualization: Data virtualization follows a federated architecture, where data remains in its original source systems, and a virtual layer is created to provide unified access and integration of data from multiple sources.
3.2 Data Storage and Processing:
– Data Lake: Data lakes store large volumes of diverse data types in a centralized repository, enabling batch processing and analytics at scale.
– Data Virtualization: Data virtualization platforms provide real-time access to data from distributed sources, allowing users to query and analyze data on-the-fly without data replication.
3.3 Flexibility and Agility:
– Data Lake: Data lakes offer flexibility in data ingestion and storage, allowing organizations to capture and store raw data from various sources without upfront data transformation.
– Data Virtualization: Data virtualization enables agile data delivery by providing self-service access to integrated data assets, empowering users to query and analyze data in a flexible and efficient manner.
4. When to Use Data Lake vs. Data Virtualization:
4.1 Use Cases for Data Lake:
– Use data lake when dealing with large volumes of raw data from diverse sources that require storage and batch processing for analytics.
– Use data lake for data science and machine learning initiatives that require centralized access to raw data for exploratory analysis and model development.
– Use data lake for scenarios where data retention and historical analysis are critical, such as regulatory compliance and long-term storage of archival data.
4.2 Use Cases for Data Virtualization:
– Use data virtualization when real-time access to distributed data sources is required for operational analytics, customer 360 view, and regulatory reporting.
– Use data virtualization for scenarios where data integration agility and flexibility are paramount, such as agile data delivery and dynamic data federation.
– Use data virtualization to complement data lake initiatives by providing real-time access to integrated data assets for interactive analytics and decision-making.
Conclusion:
Data lake and data virtualization are two distinct approaches for addressing data silos and enabling data integration and analytics in the enterprise. While data lake focuses on centralized storage and batch processing of raw data, data virtualization provides real-time access and integration of data from distributed sources. By understanding the characteristics, benefits, and use cases of each approach, organizations can make informed decisions on when to leverage data lake vs. data virtualization to meet specific business requirements and unlock the full potential of their data assets.

